文中指向
https://prosemirror.xheldon.com域名的内容,都可以通过将其替换成https://prosemirror.net来获取英文原文
翻译说明:
- 工作需要使用 ProseMirror, 但是市面上没有找到翻译完善的文档(有些翻译读起来像是机翻), 因此借着这个机会着手翻译该库的这个概念说明文档.
- 我根据之前翻译文章的一些经验来看, 为了避免歧义, 将一些
专有名词不翻译是最好的选择 - 尽量忠实于原文, 但是有些地方直接翻译会导致部分语义有些奇怪上下文不连贯, 因此在必要的时候会加上一些主语等额外信息. 或者直接意译, 读者如果有发现不通顺的地方可以查看原文.
- 过程中有些不理解的地方我在 Prosemirror 的论坛咨询过作者, 说明链接我放上去了.
- 本指南直接看估计看不明白, 建议先大致看一遍, 然后在这个仓库中看看并实现一个基本功能如 heading(node 类型) 和 加粗(marks)类型是如何实现的, 再回过头来看这篇指南印象更深刻.
- 我喜欢中文输入法使用英文标点符号.
- 有些地方我笔误将 ProseMirror 写成了 Prosemirror, 不过并不影响本指南.
- 我写了一个简单的 Demo 包含一些基本的示例方便做实验, 放在了: 这个仓库, 欢迎 fork/star.
- 中英文之间有空格, 逗号后面有空格是一般操作.
- 本人技术有限, 翻译水平有限, 认知有限, 有不当之处请各位指正, 谢谢!
译者所理解的概念说明
- Document: 即 Prosemirror 所在的整个文档, 通常 editor.view.state.doc 保持对其的引用.
- Schema: Prosemirror 的骨架对象, 定义了编辑器的各种规则来约束文档, 有时候你需要手动处理以适应这些规则, 而大部分情况下 Prosemirror 会帮你处理以适应这些规则.
- State: Prosemirror 的数据结构对象, 相当于是 react 的 state, 有 view 的 state 和 plugin 的局部 state 之分. 如上面的 schema 就定义在其上: state.schema.
- View: Prosemirror 的视图对象, 其上有一些更新视图的方法, state 是其上一个属性: view.state.
- Transform: 可以理解为存放文档变化的容器对象, 另外其上还有一些方法可以修改变化. 而 transaction 是其子类, 后者是针对整个编辑器的 state 变化的.
- Selection: 即选区对象, 什么也不选的时候可以表示光标, 有多个位置相关的属性和方法.
- Range: 多个节点对象的容器, 通常用来处理一段选区中包含多个类型的节点和 Mark 的情况.
- Slice: 主要用来处理选区选到一半时导致不符合 schema 结构的问题的对象.
- Node: Prosemirror 的基本元素, 可以通过 schema 来定义各种类型的节点, 至少包含 doc(根节点) 和 text(文本节点) 这两种节点.
- NodeType: Prosemirror 的节点类型, 一般用来新建节点用, 定义了某个类型节点上的属性.
- XXXSpec: 定义 XXX 时候的配置对象, 如 NodeSpec, MarkSpec 等.
- Mark: Prosemirror 将行内文本视作扁平结构而非 DOM 类似的树状结构说是为了方便计数和操作, 因此 Mark 表示某个行内节点的属性, 如 font-size, bold 等, 支持自定义.
- MarkType: 同节点类型, 定义了 Mark 的一些属性, 其上的一些方法可以用来创建 mark.
- DOMOutputSpec: 就是在 schema 中的 toDOM 指定的返回值, 官方说明.
- ResolvedPos: Prosemirror 解析位置信息(详见下面的位置计数一节)返回的对象, 包含了一些位置相关的信息.
- Plugin: 通常使用 Plugin 实现一些行为, 如点击/粘贴/撤销等, Plugin 还可以直接定义节点.
- Decoration: 通常用来生成与文档状态无关的视图, 可以用来做一些特效而不影响文档结构.
中英文翻译对照(可以在阅读本指南的时候相互替代)
- document 文档
- schema 骨架/文档约束
- state 状态
- view 视图
- transaction 事务/原子变更
- selection 选区
- node 节点
- mark 标记/样式属性
- plugin 插件
- decoration 装饰器
- range 选区范围
- slice 选区片段
- leaf Nodes 叶节点(如 image/hr 元素)
- mutable 可突变的
- Fragment 文档片段
- Token 标识符(如标签名等)
- type 类型
- group (元素)组
- block node 块级节点
- content 内容
- expression 表达式
- assert 断言
- attributes 属性
- step 步骤(命令的基本单位,可包含一个或多个 tr)
- set of xxx xxx 的集合
- dispatch 触发
- declare 声明
- map 映射
- textblock 文本块节点
- pipeline 管道
翻译正文开始 👇
ProseMirror 中文指南
本指南介绍了在该库中使用的各种概念, 以及它们是如何相互关联的. 为了让你对系统整体有一个印象, 推荐读者按本文的文档顺序阅读, 或者至少(如果你没有耐心而只是想大概了解的话), 读完 View 组件的那一块
介绍
ProseMirror 提供了一整套构建富文本编辑器的工具和概念, 它使用的用户界面受 所见即所得 概念的启发, 但是尽量避免陷入它样式编辑的天坑.
Prosemirror 的基本概念是, 你和你的代码对文档和文档的变化拥有绝对的控制权. 这里的文档不是 HTML 里的那一大坨杂乱无章的代码, 而是一个只包含那些你明确指定允许它包含的元素和它们之间的你指定的关系的自定义数据结构(意思就是什么元素可以出现, 元素之间的关系, 都在你的掌控之下——译者注). 所有的文档更新操作都从一个点出发, 方便你对更新做处理.
Prosemirror 的核心模块并不是开箱即用的, 在开发这个库的时候, 我们坚持它的模块化和自定义程度的优先级高于简洁性. 当然, 我们希望将来有人能开发一个基于 Prosemirror 的开箱即用的编辑器. 这种感觉打个比喻来说就是, Prosemirror 是一个乐高积木, 拿到后需要你手动拼装, 而不是像一个火柴盒一样, 打开就能使用.
Prosemirror 有四个必要的模块, 任何操作都需要这四个模块, 另外还有很多 Prosemirror 核心团队维护的扩展模块, 它们(这些扩展模块)像一些提供了很多有用功能的第三方模块一样, 都能被实现了相同功能的其他模块所取代.
上述的四个必要模块有:
- prosemirror-model 定义了编辑器的 Document Model, 它用来描述编辑器的内容.
- prosemirror-state 提供了一个描述编辑器完整状态的单一数据结构, 包括编辑器的选区操作, 和一个用来处理从当前 state 到下一个 state 的一个叫做 transaction 的系统.
- prosemirror-view 用来将给定的 state 展示成相对应的可编辑元素显示在编辑器中, 同时处理用户交互.
- prosemirror-transform 包含了一种可以被重做和撤销的修改文档的功能, 它是 prosemirror-state 库的 transaction 功能的基础, 这使得撤销操作历史记录和协同编辑成为可能.
除此之外, 还有一些模块如 基本编辑命令, 快捷键绑定, 操作历史记录及回滚, 宏命令, 协同编辑, 和一个简单的文档 Schema 等等. 更多模块可以在 Github 上的 Prosemirror 组织中发现.
Prosemirror 并不是一个浏览器可直接加载的脚本, 这意味着你需要使用一些打包工具才能使用它. 打包工具就是一个自动寻找你脚本声明的依赖, 然后合并它们到一个单独的脚本文件, 以便你能够在浏览器中方便的加载它. 你可以自己去看看更多关于 Web 打包方面的东西, 比如 这里
我的第一个编辑器
下面的代码像乐高积木一样的摞在一起创建了一个最简单的编辑器:
1 | |
Prosemirror 需要你手动指定一个 document 需要遵守的 Schema (来规定哪些元素能包含哪些不能包含以及元素之间的关系), 为了达成这个目的, 上述代码做的第一件事就是先导入一个基本的 schema(通常情况下 schema 是你自己写的, 这里作者拿了一个现成的包含基本元素的 schema 做示例——译者注).
之后, 这个基础 schema 被用来创建一个 state, 该 state 会生成一个遵守 schema 约束的一个空的文档, 以及一个默认的选区在这个文档的开头(这个选区是空的, 因此这里指的是光标). 最终, 这个 state 会生成一个 view 被 append 到 document.body. 上述的 state 的文档最终将被渲染成一个可编辑的 DOM 节点(就是 contenteditable 的节点——译者注) 和一个会对用户输入做出反应的 state transaction.
(不幸的是)到目前为止这个编辑器还不能用. 例如, 如果你在刚刚的编辑器中按 Enter 键, 则什么也不会发生, 因为上述提到的四个核心模块并不知道输入 Enter 之后应该做什么, 我们将在稍后告诉它如何响应各种输入行为.
Transactions
当用户输入的时候, 或者更广泛的说, 当用户与页面的 view 进行交互的时候, prosemirror 会产生 ‘state transactions’. 这意味着每当用户输入后, prosemirror 不仅仅只修改 document 内容, 同时还会在背后更新 state. 也就是说, 每一个变化都会有一个 transaction 被创建, 它描述了 state 被应用的变化, 这些变化可以被用来创建一个新的 state, 然后这个新的 state 被用来更新 view.
默认情况下, 上述的这些变化是框架进行的, 你无需关注. 不过你可以通过写一个 plugin 或者自定义你的 view 的方式, 来往这个变化的过程中挂载一些 hook. 举个例子, 下面的代码增加了一个 dispatchTransaction prop, 它在每一个 transaction 被创建的时候调用:
1 | |
每次的 state 更新最终都需要执行 updateState 方法, 而且每 dispatching 一个 transaction 一般情况下都会触发一个编辑状态的更新.
Plugins
Plugins 被用来以多种不同的方式扩展编辑行为和编辑状态. 一些插件比较简单, 比如 keymap 插件, 它用来绑定键盘输入的 actions. 还有些插件相对复杂一点, 比如 history 插件, 它通过监视 transactions 和按照相反的顺序存储它们以便用户想要撤销一个 transactions 来实现一个 undo/redo 的功能.
让我们先增加下面两个 plugin 以获得 undo/redo 的功能:
1 | |
Plugins 会在创建 state 的时候被注册(因为它们需要访问 state 的 transactions 的权限). 在给这个可撤销/重做的 state 创建一个 view 之后, 你将能够通过按 Ctrl+Z(或者 Mac 下 Cmd+Z) 撤销上一步操作.
Commands
上面示例中, 被绑定到相关键盘按键的的特殊的函数叫做 commands. 大多数的编辑行为都会被写成 commands 的形式, 因此可以被绑定到特定的键上, 以供编辑菜单调用, 或者暴露给用户来操作.
prosemirror-commands 这个包提供了很多基本的编辑 commands, 包括在编辑器中按照你的期望映射 enter 和 delete 按键的行为.
1 | |
到此为止, 你应该有了一个基本能 work 的编辑器了.
如果还想增加一个菜单方便编辑操作, 或者想增加一些 schema 允许的按键绑定, 诸如此类的东西, 那么你可能想要看下 prosemirror-example-setup 这个包. 这个包提供了实现一个基本编辑器的一系列设置好的插件, 不过就像这个包名所表示的含义那样, 它仅仅是用来示例一些 API 的用法, 而不是一个可以用在生产环境的包. 对于一个真实的开发环境, 你可能想要用自己的代码替换其中的一些内容, 以精确实现你想要的效果.
Content
一个 state 的 document 对象存储在 doc 属性上, 它是一个只读类型的数据结构, 用一系列的不同层级的节点表示, 这些节点的层级结构有点类似于浏览器中的 DOM 节点. 一个简单的 document 可能有一个 “doc” 节点, 它包含两个 “paragraph” 节点, 每个 “prragraph” 节点又包含一个 “text” 节点. 你可以在 guide 中读到更多关于 document 数据结构的信息.
当初始化一个 state 的时候, 你可以传给它一个初始 document. 在这种情况下, schema 字段就是可选的, 因为 schema 可以从 document 中获取.
下面的示例我们通过 DOM 格式化的机制去格式化 DOM 中 id 为 “content” 的元素来初始化一个 state, 这个 state 使用的 schema 信息是由 DOM 节点格式化后映射到相应元素上获得的(意思就是 DOM 节点包含哪些元素, 格式化后被对应成 schema 的形式供 state 使用, 因此 schema 信息可以从格式化 DOM 的信息中获取而不用手动指定——译者注).
1 | |
Documents
Prosemirror 定义了它自己的数据结构来表示 document 内容. 因为 document 是构建一个编辑器的核心元素, 因此理解 document 是如何工作的很有必要.
Structure
一个 Porsemirror 的 document 是一个 node 类型, 它含有一个 fragment 对象, fragment 对象又包含了 0 个或更多子 node.
这看起来很像浏览器 DOM 的结构, 因为 Prosemirror 跟 DOM 一样是递归的树状结构. 不过, Prosemirror 在存储内联元素的方式上跟 DOM 有点不同.
在 HTML 中, 一个 paragraph 及其中包含的标记, 表现形式就像一个树, 比如有以下 HTML 结构:
1 | |

然而在 Prosemirror 中, 内联元素被表示成一个扁平的模型, 他们的节点标记被作为 metadata 信息附加到相应 node 上:

这种数据结构显然更符合我们心中的这类文本该有的样子. 它允许我们使用字符的偏移量而不是一个树节点的路径来表示其所处段落中的位置, 并且使一些诸如 splitting 内容或者改变内容 style 的操作变得很容易, 而不是以一种笨拙的树的操作来修改内容.
这也意味着, 每个 document 只有一种数据结构表示方式. 文本节点中相邻且相同的 marks 被合并在一起, 而且不允许空文本节点. marks 的顺序在 schema 中指定.
因此, 一个 Prosemirror document 就是一颗 block nodes 的树, 它的大多数 leaf nodes 是 textblock 类型, 该节点是包含 text 的 block nodes.你也可以有一些内容为空的简单的 leaf nodes, 比如一个水平分隔线 hr 元素, 或者一个 video 元素.
Node 对象有一系列属性来表示他在文档中的角色:
isBlock和isInline告诉你这个 node 是一个 block 类型的 node(类似 div)还是一个 inline 的 node(类似 span).inlineContent为 true 表示该 node 只接受 inline 元素作为 content(可以通过判断此节点来决定下一步是否往里面加 inline node or not——译者注)isTextBlock为 true 表示这个 node 是个含有 inline content 的 block nodes.isLeaf为 true 表示该 node 不允许含有任何 content.
因此, 一个典型的 “paragraph” node 是一个 textblock 类型的节点, 然后一个 blockquote(引用元素)则是一个可能由其他 block 元素构成其内容的 block 元素. Text 节点, 回车, 和 inline 的 images 都是 inline leaf nodes, 而水平分隔线(hr 元素)节点是一个典型的 block leaf nodes.(leaf nodes 翻译成 叶节点, 表示其不能再含有子节点; leaf nodes 如上所说, 可能是 inline 的, 也可能是 block 的——译者注).
Schema 允许你可以对诸如"哪些元素允许出现在哪些地方"这种问题指定更多的约束条件. 例如, 即使一个 node 允许 block content, 那也不意味着它允许所有的 block nodes 作为 content(你可以通过 schema 手动指定例外——译者注).
Identity and persistence
DOM 树与 ProseMirror document 的另一个不同是他们对 nodes 对象的表示方式. 在 DOM 中, nodes 是带有 identity 的 mutable 对象(不知道 mutable 对象是啥的可以搜索下), 这意味着一个 node 只能出现在它的父级 node 下(如果它出现在别处, 那它在此处就没了, 因为有 identity, 所以唯一——译者注), 当这个 node 更新的时候, 它就 mutated 了(node 更新是在原来的 node 上更新, 此谓之 mutated 即突变. 表示在原有基础上修改, 修改前后始终是一个对象——译者注).
而在 Prosemirror 中却不同, nodes 仅仅是 values(区别于 DOM 的 mutable, values 是 unmutable 的), 表示一个节点就像表示一个数字 3 一样. 3 可以同时出现在不同的数据结构中, 它不跟当前的数据结构绑定, 如果你对它增加 1, 你将会得到一个新的 value: 4 而不用对原始的 3 做任何修改.
所以这就是 Prosemirror document 的机制. 它的值不会改变, 而且可以被当做一个原始值去计算一个新的 document. 这些 document 的 nodes 们不知道它所处的数据结构是什么, 因为它们可以存在于多个结构中, 甚至可以在一个结构中重复多次. 它们是 values, 不是拥有状态的对象.
这意味着每次你更新 document, 你就会得到一个新的 document. 这个新的 document 共享旧的 document 的所有没有在这次更新中改变的子 nodes 的 value, 这让新建一个 document 变得很廉价.
这种机制有很多优点. 它让当 state 更新的时候编辑器始终可用, 因为新的 state 就代表了新的 document(如果更新未完成, 则 state 不会出现, 因此 document 也没有, 编辑器仍然是之前的 state + document——译者注), 新旧状态可以瞬间切换(而没有中间状态). 这种状态切换更可以以一种简单的数学推理的方式完成——而如果你的值在背后不断变化(指像 DOM 的节点一样突变——译者注), 这种推理将非常困难. Prosemirror 的这种机制使得协同编辑成为可能, 而且能够通过比较之前绘制在屏幕上的 document 和当前的 document 算法来非常高效的 update DOM.
因为 nodes 都被表示为正常的 JavaScript 对象, 而明确 freezing 他们的属性(防止 mutate)非常影响性能, 因此事实上虽然 Prosemirror 的 document 以一种非突变的机制运行, 但是你还是能够手动修改他们. 只是 Prosemirror 不支持这么做, 如果你强行 mutate 这些数据结构的话, 编辑器可能会崩溃, 因为这些数据结构总是在多处共享使用(修改一处, 影响其他你不知道的地方——译者注). 因此, 务必小心!!! 同时记住, 这个道理对一些 node 对象上存储的数组和对象同样适用, 比如 node attributes 对象, 或者存在 fragments 上的子 nodes.
Data structures
一个 document 的数据结构看起来像下面这样:
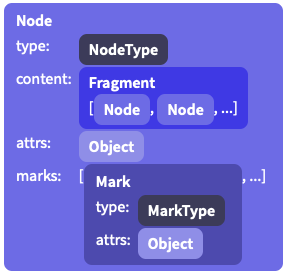
每个 node 都是一个 Node 类的实例. 它们用 type 属性进行归类, 通过 type 属性可以知道 node 的名字, 它可以使用的 attributes, 诸如此类的信息. Node types(和 mark types) 只会被每个 schema 创建一次, 它们知道自己是属于哪个 schema.
node 的 content 被存储在一个指向 Fragment 实例的字段上, 它的内容是一个 nodes 数组. 即使那些没有 content 或者不允许有 content 的 nodes 也是如此, 这些不许或没有 content 的节点被共享的 empty fragment 替代.
一些 nodes 类型允许有 attributes, 它们在每个 nodes 上以(不同于 content 的)额外的值存储着. 例如, 一个 image node 可能使用 attributes 存储 alt 文本信息和 URL 信息.
除此之外, inline nodes 含有一些激活的 marks——marks 就是指那些像 emphasis 或者 一个 link 的东西——它们被表示成 Mark 实例.
整个 document 都是一个 node. document 的 content 作为顶级 node 的子 nodes. 通常上来说, 这些顶级 node 的子 node 是一系列的 block nodes, 这些 block nodes 中有些可能包含 textblocks, 这些 textblocks 有包含 inline content. 不过, 顶级 node 也可以只是一个 textblock, 这样的话整个 document 就只包含 inline content.
哪些 node 被允许出现在哪些位置是由 document 的 schema 决定的. 为了用编程的方式(而不是直接对编辑器输入内容的方式——译者注)创建 nodes, 你必须遍历 schema, 比如下面的使用 node 和 text 方法.
1 | |
Indexing
Prosemirror nodes 支持两种类型的 indexing——它们既可以被当成树类型, 因为它们使用 offsets 来区别每个 nodes; 也可以被当成一个具有一系列 token 的扁平的结构(token 可以理解为一个计数单位).
第一种 index 允许你像在 DOM 中那样, 与单个 nodes 进行交互, 使用 child method 和 childCount 直接访问 child nodes, 写递归函数去遍历 document(如果你想遍历所有的 nodes, 使用 descendants 和 nodesBetween).
第二种 index 当在文档定位一个指定的 position 的时候更有用. 它可以以一个整数表示文档中的任意位置——这个整数是 token 的顺序. 这些 token 对象在内存中其实并不存在——它们只是用来计数方便——不过 document 的树状结构以及每个 node 都知道它们自己的大小尺寸使得按位置访问它们变得廉价.
- Document 的起始位置, 在所有 content 的开头, 位置是 0.
- 进入或者离开不是 leaf node 的节点(比如能够包含内容的节点, 都算是非 leaf node)计为 1 个 token. 所以如果 document 以一个 paragraph(标签是 p) 开头, 在段落开头的 position 是 1(即
<p>之后的位置——译者注) - Text nodes 的每个字符记为 1 个 token. 所以如果在 document 的开头的 paragraph 包含单词 “hi”, 那么 position 2 在 “h” 之后, position 3 在 “i” 之后, position 4 在整个段落之后(即
</p>之后——译者注) - Leaf nodes 如果不允许 content 的(比如图片节点), 计做 1 个 token.
因此, 如果你有一个 document, 表示成 HTML 就像下面这样:
1 | |
Token 顺序和 position 则看起来像下面这样:

每个 node 都有一个 nodeSize 属性表示整个 node 的尺寸大小, 你还可以通过 .content.size 获得 node 的 content 的尺寸大小. 需要注意的是对于 document 的外层节点(即 DOM 中 contenteditable 属性所处的节点, 是整个 document 的根节点——译者注)来说, 开始和关闭 token 不被认为是 document 的一部分(因为你无法将光标放到 document 的外面), 因此 document 的尺寸是 doc.content.size, 而不是 doc.nodeSize(虽然 document 的开关标签不被认为是 document 的一部分, 但是仍然计数. 后者始终比前者大 2——译者注).
如果手动计算这些位置涉及到相当数量的计算工作. (因此)你可以通过调用 Node.resolve 来获得一个 position 的更多数据结构的描述. 这个数据结构将会告诉你当前 position 的父级 node 是什么, 它在父级 node 中的偏移量是多少, 它的父级 node 的祖先 nodes 有哪些, 和其他一些信息.
一定要注意区分子 node 的 index(比如每个 childCount), document 范围的 position, 和 node 的偏移(有时候这个偏移会用在一个递归函数表示当前处理的 node 的位置, 此时就涉及到 node 的偏移)之间的区别.
Slices
对于用户的复制粘贴和拖拽之类的操作, 涉及到一个叫做 slice of document 的概念(文档片段——译者注), 例如在两个 position 之间的 content 就是一个 slice. 这种 slice 与一个完整的 node 或者 fragment 不同, slice 可能是 “open”(意思即一个 slice 包含的标签可能没有关闭, 比如 <p>123</p><p>456</p> 中, 一个 slice 可能是 23</p><p>45 ——译者注).
例如, 如果你用光标选择从一个段落的中间到另一个段落的中间, 那么你选择的 slice 就是含有两个段落, 第一个在开始的地方 open, 第二个在结束的地方 open, 然后如果你使用接口(而不是通过与 view 交互——译者注)选择了一个段落 node, 那你就选择了一个 close 的 node. 如果对待 slice 像普通的 node content 一样的话, 它的 content 可能不符合 schema 的约束, 因为某些所需要的 nodes(如使 slice content 是一个完整的 node 的标签, 如上例中的开始部分的 <p> 和结束部分的 </p>) 落在了 slice 之外.
Slice 数据结构就是被用来表示这种的数据的. 它存储了一个含有两侧 open depth (意思就是相对于根节点的层级深度——译者注)信息的 fragment. 你可以在 nodes 上使用 slice method 来从 document 上 “切” 出去一片 “slice”.
1 | |
Changing
因为 nodes 和 fragment 是一种持久化的数据结构(意即 immutable ——译者注), 你绝对不应该直接修改他们. 如果你需要操作 document, 那么它就应该一直不变(操作后产生新的 document, 旧的 document 一直不变——译者注).
大多数情况下, 你需要使用 transformations 去更新 document 而不用直接修改 nodes. 这也方便留下一个变化的记录, 变化的记录对作为编辑器 state 一部分的 document 是必要的.
如果你非要去手动更新 document, Prosemirror 在 Node 和 Fragment 上提供了一些有用的辅助函数去新建一个 document 的全新版本. 你可能会常常用到 Node.replace 方法, 该方法用一个含有新的 content 的 slice 替换指定 document 的 range 内的内容. 如果想要浅更新一个 node, 你可以使用 copy 方法, 该方法新建了一个相同的 node, 不过为这个相同的新 node 可以指定新的 content. Fragments 也有一些更新 document 的方法, 比如 replaceChild 和 append.
Schemas
每个 Prosemirror document 都有一个与之相关的 schema. 这个 schema 描述了存在于 document 中的 nodes 类型, 和 nodes 们的嵌套关系. 例如, schema 可以规定, 顶级节点可以包含一个或者更多的 blocks, 同时段落 paragraph nodes 可以包含含有任意数量的 inline nodes, 这些 inline nodes 可以含有任意数量的 marks.
关于 schema 的用法, 这里有一个 basic schema 的包可以作为示例看一下, 不过 Prosemirror 有个比较棒的点在于它允许你定义你自己的 schemas.
Node Types
在 document 中的每个节点都有一个 type, 它代表了一个 node 的语义化上意思和 node 的属性, 这些属性包括在编辑器中的渲染方式.
当你定义一个 schema 的时候, 你需要列举每一个用到的 node types, 用一个 spec object 描述它们:
1 | |
上述代码定义了一个允许 document 包含一个或更多 paragraphs 的 schema, 每个 paragraph 又能包含任意数量的 text.
每个 schema 至少得定义顶级 node 的 type(顶级 node 的名字默认是 “doc”, 不过你可以配置它), 和规定 text content 的 “text” type.
作为 inline 类型来计算 index 等的 nodes 必须声明它的 inline 属性(回想一下 text 类型, 它就被定义成 inline 了——这一点你可能忽略了)
Content Expressions
上面 schema 示例代码中的 content 字段的字符串值被叫做 ‘content expressions’. 他们控制着对于当前 type 的 node 来说, 哪些 child nodes 类型可用.
比如说, (content 字段的内容是)“paragraph” 意思就是 “一个 paragraph”, “paragraph+” 意思就是 “一个或者更多 paragraph”.与此相似, “paragraph*” 意思就是 “0 个或者更多 paragraph”, “caption?” 意思就是 “0 个或者 1 个 caption node”. 你也可以在 node 名字之后使用类似于正则表达式中表示范围含义的表达式, 比如 {2}(正好 2 个), {1, 5}(1 个到 5 个), 或者{2, }(两个或更多).
这种表达式可以被联合起来创建一个系列, 例如 “heading paragraph+” 表示 “开头一个 heading, 之后一个或更多 paragraphs”. 你也可以使用管道符号 “|” 操作符来表示在两个表达式中选择一个, 比如 “(paragraph | blockquote)+”.
一些元素 type 的 group 可能在你的 schema 会出现多次, 比如你有一个 “block” 概念的 nodes, 他们可以出现在顶级元素之下, 也可以嵌套进 blockquote 类型的 node 内. 你可以通过指定 schema 的 group 属性来创建一个 node group, 然后在你的其他表达式中填 group 的名字即可:
1 | |
上面示例中, “block+” 等价于 “(paragraph | blockquote)+”.
建议在允许 block content 的 nodes(在示例中就是 doc 和 blockquote)中设置为至少有一个 child node, 因为如果 node 为空的话浏览器将折叠它, 使它无法编辑(这句话的意思是, 如果上述 doc 或者 blockquote 的 content 设置为 block* 而不是 block+ 就表示允许不存在 child nodes 存在的情况(它沿用了通用的正则符号: * 表示 0 个或更多, + 表示 1 个或更多), 那么此时编辑的话浏览器输入的是 text node, 是 inline 节点, 导致无法输入, 读者可以试试——译者注).
在 schema 中, nodes 的书写顺序很重要. 当对一个必选的 node 新建一个默认实例的时候, 比如在应用了一个 replace step 之后, 为了保持当前文档仍然符合 schema 的约束, 会使用能满足 schema 约束的第一个 node 的 expression. 如果 node 的 expression 是一个 group, 则这个 group 的第一个 node type(决定于当前 group 的成员 node 出现在 schema 的顺序)将被使用. 如果我在上述的 schema 示例中调换了 “paragraph” 和 “blockquote” 的顺序, 当编辑器试图新建一个 block node 的时候将会报 stack overflow——因为编辑器会首先尝试新建一个 “blockquote” node, 但是这个 node 需要至少一个 block node, 于是它就首先又需要创建一个 “blockquote” node 作为内容, 以此往复.
不是每个 Prosemirror 库中的 node 操作函数都会检查它当前处理 content 的可用性——高级概念例如 transforms 会检查, 但是底层的 node 新建方法通常不会, 这些底层方法通常将可用性检查交给它们的调用者. 它们(即使当前操作的 content 不可用, 但是这些底层方法也)完全可能可用, 比如, NodeType.create, 它会创建一个含有不可用 content 的节点. 对于在一个 slices 的 “open” 一边的 node 而言, 这甚至是情有可原的(因为 slice 不是一个可用的节点, 但是又需要直接操作 slice ——总不能让用户手动补全吧?——译者注). 有一个 createChecked 方法可以检查给定 content 是否符合 schema, 也有一个 check 方法来 assert 给定的 content 是否可用.
Marks
Marks 通常被用来对 inline content 增加额外的样式和其他信息. schema 必须声明当前 document 允许的所有 schema(就像声明 nodes 那样——译者注). Mark types 是一个有点像 node types 的对象, 它用来给不同的 mark 分类和提供额外的信息.
默认情况下, 允许有 inline content 的 nodes 允许所有的定义在 schema 的 marks 应用于它的 child nodes. 你可以在 node spec 中的 marks 字段配置之.
下面是一个简单的 schema 示例, 支持在 paragraphs 中设置文本的 strong 和 emphasis marks, 不过 heading 则不允许设置这两种 marks.
1 | |
marks 字段的值可以写成用逗号分隔开的 marks 名字, 或者 mark groups——“_”, 它是通配符的意思, 允许所有的 marks. 空字符串表示不允许任何 marks.
Attributes
Document 的 schema 也定义了 node 和 mark 允许有哪些 attributes. 如果你的 node type 需要外的 node 专属的信息, 比如 heading node 的 level 信息(H1, H2 等等——译者注), 此时适合使用 attribute.
Attribute 是一个普通的纯对象, 它有一些预先定义好的(在每个 node 或 mark 上)属性, 指向可以被 JSON 序列化的值. 为了指定哪些 attributes 被允许出现, 可以在 node spec 和 mark 的 spec 中使用可选的 attr 属性:
1 | |
在上面这个 schema 中, 每个 heading node 实例都有一个 level 属性通过 .attrs.level 访问. 如果在新建 heading 的时候没有指定, level 默认是 1.
如果你在定义 node 的时候没有给一个 attribute 默认值的话, 当新建这个 node 的时候, 如果没有显式传入 attribute 就会报错. 这也让 Prosemirror 在调用一些接口如 createAndFill 来生成满足 schema 约束的 node 的时候变得不可能.
Serialization and Parsing
为了能在浏览器中编辑元素, 就必须使 document nodes 以 DOM 的形式展示出来. 最简单的方式就是在 schema 中对每个 node 注明如何在 DOM 中显示. 这可以在 schema 的每个 node spec 中指定 toDOM 字段来实现.
这个字段应该指向一个函数, 这个函数将当前 node 作为参数, 返回 node 的 DOM 结构描述. 这可以直接是一个 DOM node, 或者一个 array 来描述, 例如:
1 | |
上面示例中, [“p”, 0] 的含义是 paragraph 节点在 HTML 中被渲染成
标签. 0 代表一个 “hole”, 表示该 node 的内容应该被渲染的地方(意思就是如果这个节点预期是有内容的, 就应该在数组最后写上 0). 你也可以在标签后面加上一个对象表示 HTML 的 attributes, 例如 [“div”, {class: “c”}, 0]. leaf nodes 不需要 “hole” 在它们的 DOM 中, 因为他们没有内容.
Mark 的 specs 有一个跟 nodes 相似的 toDOM 方法, 不同的是他们需要渲染成单独的标签去直接包裹着 content, 所以这些 content 直接在返回的 node 中, 所以上面的 “hole” 就不用专门指定了.
你也会经常格式化 HTML DOM 的内容为 Prosemirror 识别的 document. 例如, 当用户粘贴或者拖拽东西到编辑器中的时候. Prosemirror-model 模块有些函数来处理这些事情, 不过你也应该有勇气在 schema 中的 parseDOM 属性中直接包含如何格式化的信息.
这里列出了一组格式化的规则, 描述了 DOM 如何映射成 node 或者 mark. 例如, 基本的 schema 对于 emphasis mark 写成下面这样:
1 | |
上面中的 parse rule 的 tag 字段也可以是一个 CSS selector, 所以你也可以传入类似于 “div.myclass” 这种的字符串. 与此相似, style 字段匹配行内 CSS 样式.
当一个 schema 包含 parseDOM 字段时, 你可以使用 DOMParser.fromSchema 创建一个 DOMParser 对象. 编辑器在新建默认的剪切板内容 parser 的时候就是这么干的, 不过你可以覆盖它.
Document 也有一个内置的 JSON 序列化方式. 你可以在 node 上调用 toJSON 来生成一个可以安全地传给 JSON.stringify 函数的对象(感觉这个目的是为了方便调试?——译者注), 此外 schema 对象有一个 nodeFromJSON 方法可以将 toJSON 的结果再转回原始的 node.
Extending a schema
传给 Schema 构造器来设置 nodes 和 marks 选项的参数可以是 OrderedMap 类型的对象, 也可以是纯 JavaScript 对象. 生成的 schema 上的 .spec.nodes 和 .spec.marks 属性则总是 OrderedMaps, 它可以被用来作为其他 schemes 的基础.
OrderedMaps 这种 map 支持很多方法去方便的新建新的 schema. 比如, 你可以通过调用 schema.markSpec.remove(“blockquote”) 后, 将调用结果传给 Schema 构造器的参数的 nodes 字段, 来生成一个没有 blockquote node 的 schema.
Document transformations
Transform 是 Prosemirror 的核心工作方式. 它是 transactions 的基础, 其使得编辑历史跟踪和协同编辑成为可能.
Why?
为什么我们不能直接对 document 进行修改(突变 mutate)? 或者至少新建一个全新版本的 document 然后将其放到编辑器中去呢?
有好几个原因. 其中之一就是代码清晰度. Immutable 数据结构确实可以造就简单的代码. 而且 transform 系统做的主要工作就是保留了 document 更新的痕迹, transform 的一系列值代表了从旧的 document 到新的 document 的每一个 steps 记录.
Undo History 可以保存这些 steps 然后在需要的时候反过来应用这些 steps ( Prosemirror 实现了可选择的 undo, 这比仅仅回滚之前的 state 状态更为复杂)
Collaborative editing (协同编辑)系统发送这些 steps, 并在必要的时候记录这些 steps, 以便每个 document 编辑者都能够有相同的 document.
在大多数情况下, 能够对每个 document 改变(无论是来自自己还是来自协同编辑)做出相应反应对 editor plugin 来说是很有用的, 这始终能够让插件保持与 editor 的 state 同样的状态.
Steps
对于 document 的更新会被分解成一个个的 steps, 它描述了一个更新. 你一般情况下不需要直接与它打交道, 不过知道它们如何工作的原理是很有必要的.
Steps 的一个例子就是 ReplaceStep, 它可以替换 document 的一小部分, 或者 AddMarkStep, 可以对一个 range 应用 Mark.
一个 Step 可以被 applied 到一个 document, 然后产生一个新的 document
1 | |
应用一个 step 想对来说是比较简单的过程——它不做一些诸如插入 nodes 以保持 schema 的约束, 或者转换 slice 让其去适应 schema 之类的操作. 这意味着应用一个 setp 可能会失败. 比如如果你试图删除一个 node 的其中一个 token(就是一个 node 的开或关标签——译者注), 这将会使该 node 的另一个 token 未正确关闭, 这么做对你来说是没什么意义的. 这也就是为什么 apply 方法返回一个 result object, (如果 step apply 成功则)保持对新的 document 的引用, 或者(失败的时候)包含一个错误信息.
你通常想要让 helper function 去为你生成 steps, 这样你就不用担心一些细节.
Transforms
一个编辑行为可能会产生一个或者多个 steps. 处理一系列 step 最方便的方式是新建一个 Transform object(或者, 如果你在处理编辑器的整体 state, 可以使用 Transaction, 它是 Transform 的一个子类)
1 | |
大多数的 transform 方法返回 transform 本身, 让你能够方便的链式调用(如 tr.delete(5, 7).split(5)).
Transform 有一些方法如 deleteing 和 replaceing, adding 和 removeing marks, 操作树数据结构的方法如 splitting, joining, lifting, 和 wrapping, 以及其他.
Mapping
当你对一个 document 做出改动的时候, 指向 document 的一些 position 可能会变得不可用或者失去了原有的含义. 比如, 你插入了一个字符, 然后在这个字符后面的所有字符的 position 都会加 1, 即后面的字符指向了一个新的 position. 与此类似, 如果你删除了 document 的所有 content, 之前指向 content 的 position 都变得不可用了.
我们经常确实需要在 document 变化的过程中保持住 position(而不论它们如何变化——译者注), 比如一个 selection boundaries(选区边界, 选区有一些位置信息如 from 和 to, 文档变化的时候, 这些 from 和 to 也有时候需要随着变化, 不然选区位置信息就错了——译者注). 为了处理这个问题, steps 可以给你一个 map, 它能转换应用 step 之前和之后的在 document 的位置信息.
1 | |
Transform 对象自动 accumulate(累计计算) 一系列 setp 产生的 map, 它使用一个叫做 Mapping 的抽象来实现它, 它收集一系列的 step 的 maps 同时允许你一次性 map 它们所有.
1 | |
但是有个问题是, 对于一个给定的 position, 它应该去 map 到哪儿去(即有可能当前 position 刚好落到了一个 change 的中间位置, 分隔两半后的节点中, 前面节点的最后和后面节点的最前在 map 之前的 position 看起来它向左和向右 map 都是 OK 的, 因此这里需要有个约定——译者注). 看一下上面示例的最后一行. 位置 10 恰好处在一个 node 分隔的位置, 这个位置被插入了两个 token. 那它应该被 map 到插入内容的前面还是后面呢? 在这个示例中, 它显然被放到了插入内容的后面.
不过有些时候你想要一些不同的 map 行为, 这就是为什么 map 方法 在 setp map 和 mapping 的时候接受第二个参数: bias, 你可以将其设置为 -1, 让插入的 position 在插入后放到插入内容的前面.
1 | |
把每个单独的 step 做成小而直接的原因就是为了让这种 mapping 成为可能, 同时以无损方式 inverting step, 并将 step mapping 到彼此的 position maps.
Rebasing
(这节内容说实话没彻底搞懂啥意思, 所以我是完全按照文档翻译过来的, 没有加入自己的理解, 如有不正确的地方欢迎指正——译者注)
当做一些更复杂的关于 steps 和 maps 相关的事情的时候, 例如实现你自己的变化跟踪, 或者集成一些协同编辑方面的特性, 你就会需要 rebase step.
你可能不想麻烦自己学这部分内容直到你确定你真的需要它.
Rebasing, 以一个简单的例子来说, 就是当同一个文档被两个 step 修改的时候, 转换其中一个 step 使它能应用到被另一个 step 修改过的 document 上, 伪代码如下:
1 | |
Steps 有一个 map 方法, 该方法给出一个 mapping, 通过它来 map 整个 step. 这个 map 的过程可能会失败, 因为一些 step 在被 mapping 的时候可能已经没有意义了, 比如说, 它想 apply 的内容已经被删除了. 不过当这个 mapping 过程成功的时候, 你会有一个 step 指向一个新的 document, 也就是你 map 过的新的 document. 因此在上面的伪代码示例中, rebase(stepB, mapA) 可以简单的通过 stepB.map(mapA) 来调用
如果你想 rebase 一个链式调用的 steps 到另一个链式调用的 steps 上的时候:
1 | |
我们可以 map stepB1 到 stepA1 然后到 stepA2, 最后到 setpB1’ 不过对于 stepB2 而言, 它始于由 stepB1(doc) 产生的 document 中, 并且后者 mapped 的版本必须应用到 stepB1’(docA) 产生的 document 上去, 那事情就变得更加的麻烦了. 它必须通过下面的链式 maps 来 mapped:
1 | |
比如, 首先, stepB1 的 map 的反转让 document 回到了起始 document, 然后(stepB1)应用了 stepA1 和 stepA2 而产生的 map 流(链式调用), 最后通过应用了 setpB1 产生的 map 让 document 变成了 docA.
如果这里有一个 setpB3, 我们可以通过之前的 map 流获得 stepB3 的 map 流, 在(这个流)前面加上 invert(mapB2) 然后把 mapB2’ 放到流的末尾, 以此类推.
不过, 当 stepB1 插入了一些内容, 然后 stepB2 对这些内容做了一些事情的时候, 通过 invert(mapB1) mapping 的 stepB2 将会返回 null, 因为 stepB1 的反转删除了它即将应用的内容. 不过, 这个内容稍后将会被 mapB1 重新引入流中. mapping 这个抽象对象提供了追踪这种流的途径, 包括在它(pipline)中反转相关的 maps 的方法. 你可以通过 mapping 对象来 map step 以便解决上面所述的场景.
即使你有一个已经 rebase 的 step, 也不能保证它在应用到当前 document 的时候仍然可用. 例如, 你的 step 增加了一些 mark, 但是另一个 step 修改了你想要增加 mark 内容的父级节点, 使这个父级节点变成不允许之前 step 增加 mark 的节点, 试着 apply 你的 step 将会失败. 对这种情况更合适的处理是直接把这个 step 删掉.
The editor state
editor 的 state 是由什么组成的? 当然, 你已经有了一个组成它的 document. 不过还有一个 selection(来组成 state). 而且还要有一个方式可以存储 marks 设置的变更, 比如当你还没有开始编辑时, 启用或者禁用一个 mark 的时候.(即是为了满足一个常见的需求: 先点击 mark(如 bold/font-size 等, 然后再编辑))
Prosemirror 的 state 主要有三个 components, 它们存在于 state 对象上: doc, selection 和 storeMarks.
1 | |
不过, plugins 可能也需要存储 state. 例如, undo history 插件需要保存改变的历史. 这也就是为什么把激活的插件的设置也存储到 state 中的原因, 这些插件还可以定义自己的 slot 以存储自己的 state.
Selection
Prosemirror 支持多种类型的 selection(并且允许第三方代码定义新的 selection 类型). 这些不同类型的 Selections 以 Selection 子类的形式出现. 和 document 以及其他一些 state-related 的值一样, 它们都是 immutable 的, 也就是说为了改变一个 selection, 你需要新建一个新的 selection 对象, 以及一个新的 state 去持有它.
Selection 至少有一个开始(.form)和一个结尾(.to)的 position 指向当前 document 中. 很多 selection 类型也区分 anchor(选区固定的一侧) 和 head(选区不固定的一侧), 所以这些属性都存在于每个 selection 对象上.
最常用的 selection 类型是 text selection, 它被用来表示正常的光标(当 anchor 和 head 相同的时候) 或者选择文本. text selection 的两端都需要在 inline 的 position, 比如, 允许 inline content 的 nodes 中.
Prosemirror 的核心库也支持 node selection, 该 selectin 表示一个单独的 node 被选择的时候. 比如, 当你在一个 node 按 ctrl/cmd + click 的时候. 这个类型的 selection range 是该 node 的前面到节点之后的位置.
Transactions
在正常编辑期间, 新的 state 来源于由旧的 state. 你可能遇到过以下这种情况, 比如载入一个 document 的时候, 想要新建一个全新的 state, 那这就是个例外(即不是从旧的派生出来的——译者注).
state 通过 appling 和 transaction 一个已有的 state 来更新, 以产生一个新的 state. 概念上讲, 它们只发生一次: 给定一个旧的 state 和 变更的 transaction, 然后 state 的每个 component 的新的值被计算出来, 它们组成新的 state 的值.
1 | |
Transaction 是 Transform 的子类, 它继承了更新 document 的方法——通过 applying steps 到上一个 document 上. 除此之外, transaction 还跟踪 selection 和其他 state 相关的 components, 有一些 selection 相关的方便的方法如 replaceSelection.
新建一个 transaction 最简单的方式就是在编辑器的 state 对象上调用 tr getter(就是 view.state.tr ——译者注). 它基于当前 state 新建了一个空的 tr, 这样你就可以增加 steps 和其他更新到 tr 中去.
默认情况下, 旧的 selectin 通过每个 step 被 mapped, 然后产生一个新的 selection, 不过使用 setSelection 来精确设置一个新的 selection 也是可以的.
1 | |
与此相似, 激活的 marks 集合(即 storeMarks) 在文档或者 selection 改变的时候会自动清除, 它可以重新被 setStoredMarks 和 ensureMarks 设置.
最终, scrollInteView 方法可以保证下次 state 被(浏览器)绘制在当前视图中. 你可能想要在大多数用户操作后都调用一次.
和 Transform 的方法一样, 大多数的 Transaction 为了方便的链式调用, 返回 transaction 本身.
Plugins
当 creating 一个新的 state 的时候, 你可以提供一个数组插件. 它将会存在于任何 state 中, 这些 plugin 会影响 transaction applied 和 state 的行为方式.
Plugins 是 Plugin 类的实例, 它可以实现各种各样的特性. 最简单的是为了响应一个事件而增加一些 props 到 editor view 中, 复杂一点的就是增加一个新的 state 到 editor 中, 并基于 transaction 更新之.
当新建一个 plugin 的时候, 你需要传递 一个对象 来指定它的行为:
1 | |
当一个 plugin 需要它自己的 state slot(用 Vue 的说法就是, 作用域插槽——译者注), 它可以定义自己的 state 属性:
1 | |
上面示例中, 这个插件简单的计算了应用到 state 的 transaction 数量, 这个辅助函数使用了插件的 getState 方法, 其可以从 editor 的 state 对象上获取 plugin 的 state.
因为 editor 的 state 是一个持久化不可突变(immutable)对象, 且 plugin state 是它的一部分, 因此 plugin state 的值也一定是 immutable 的.例如, 如果 plugin 的 state 需要改变的话, apply 方法必须返回一个新的值, 而不是改变旧值, 并且没有其他代码应该改变他们.
对 plugin 来说, 在 transaction 上增加一些额外的信息通常是比较有用的. 例如, undo history, 当执行一个 undo 操作的时候, 将在执行结果的 transaction 上添加一个标记, 当 plugin 检测到这个标记的时候, 将这个 transaction 特殊对待, plugin 将会移除 undo stack 顶部的 item, 同时增加这个 transaction 到 redo stack, 而不是正常的 change 当前 document.
为了实现这个目的(在 transaction 上添加额外信息), transaction 允许 metadata 附加其上. 我们可以更新 transaction 计数插件(就是上面那个示例——译者注), 让它不要计算被标记的 transaction, 就像下面这样:
1 | |
metadata 的 keys 字段可以是字符串, 不过要避免命名冲突, 强烈建议你使用 plugin 对象(即 PluginKey 对象, 原理类似 Symbol) 有些键已经被 Prosemirror 占用了, 比如 “addToHistory”, 它可以被设置成 false, 表示阻止一个 transaction undo. 当处理一个 paste 事件的时候, editor 将会设置 transaction 的 paste 属性 为 true.
The view component
Prosemirror 的 editor view 是一个用户界面的 component, 它展示 editor state 给用户, 同时允许用户对其执行编辑操作.
上面说的 “编辑操作” 的定义, 对于核心 view component 来说会更窄一些, 它(view component)直接处理编辑界面的交互, 例如点击输入复制粘贴和拖拽. 除此之外就没有很多了. 这意味着其他一些事情, 例如展示一个菜单或者提供一个键盘绑定, 或者在核心视图组件之外做出响应 view component 就无法实现, 这就需要通过插件来实现.
Editable DOM
编辑器允许我们指定 DOM 的一部分为 editable, 这个属性会允许 (该 DOM 的一部分)被 focus 和 selection, 这使得在其中输入内容成为可能. view component 创建了一个 document 的 DOM 表示,(默认情况下使用你 schema 的 toDOM 方法), 同时使它可编辑。当可编辑的元素被 focus 的时候, Prosemirror 确保 DOM 的 Selection 与 editor state 的 selection 相符.
对于大多数的 DOM 事件, 也有很多注册事件函数可以使用, 这些注册函数转换事件到合适的 transaction. 例如, 当粘贴的时候, 粘贴内容被格式化为 Prosemirror 文档的 slice, 然后插入到文档中去.
大多数的事件也被允许直接被用户处理(而不是被 Prosemirror 封装一层), 然后再用 Prosemirror 的数据模型重新解释一遍. 例如, 对浏览器来说, 它是相当擅长处理光标和选区的位置的(尤其是当面对 bidirectional text 的时候), 因此大多数的光标移动相关的按键和鼠标事件都交给浏览器处理了, 处理完了之后 Prosemirror 才开始检查当前 DOM 的 selection 应该符合哪种类型的 text selection. 如果检测到实际的 selection 跟 Prosemirror 现在的 selection 不一致, 一个更新 selection 的 transaction 将会被 dispatched.
输入事件通常情况下也会交给浏览器去做, 因为干涉输入事件会使一些手机上的拼写检查和首字母大写以及一些其他原生特性不可用. 当浏览器更新 DOM 的时候, editor 会检测到, 然后重新格式化 document 变化的部分, 然后把这些变化的部分转化成 transaction.
Data flow
所以呢, editor view 展示了一个给定的 editor state, 同时当一些事件发生的时候, 它新建一个 transaction 然后广播之(广播这个新建的 transaction 供其他 plugin 或事件使用——译者注). 然后这个 transaction 正常情况下会被拿来创建一个新的 state, 然后这个新的 state 被 view 的 updateState 方法使用:
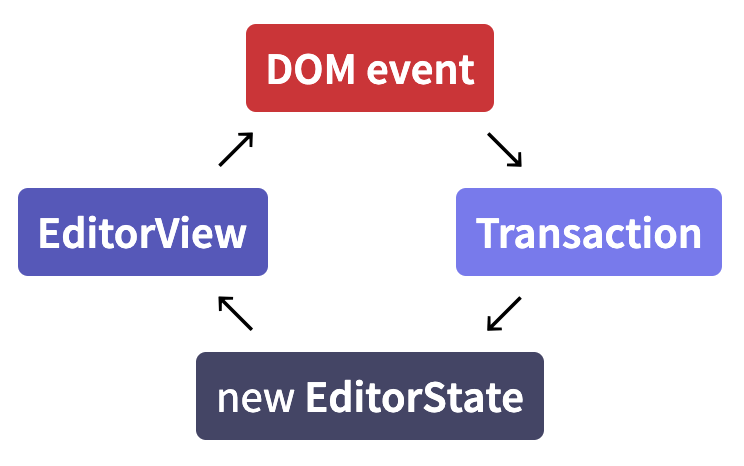
如图所示, Prosemirror 创建了一个简单的循环数据流, 它与典型的命令式的事件处理的实现方式(在 JavaScript 界) 是完全不同的, 后者往往会创建一个更复杂的数据流网络.
“拦截” transactions 是可能的, 因为它们通过 dispatchTransaction 属性被 dispatched, 为了能够让 Prosemirror 的数据流进入到更大的数据循环——如果你整个 app 使用像 Prosemirror 类似的数据流的话(如 React/Vue 这种视图框架的数据流——译者注), 例如 Redux 和其他相似的架构, 你可以集成 Prosemirror 的 transaction 到你的主要事件 dispatch 循环中去, 并且将 Prosemirror 的 state 放到你应用的 ‘store’ 中(这里借用了 Redux 的 store 概念——译者注).
1 | |
Efficient updating
实现 updateState 功能的一种途径是在每次调用它的时候重新渲染整个 document. 但是对于一些较大的 document, 这将会非常慢.
因此, 当更新 view 的时候, view 将比较的 document 和新的 document, 然后旧的 document 中那些 DOM 没有变化的部分被保留下来(而新的被替换掉——译者注). Prosemirror 替你做了这些事情, 它让每次更新只需要做很小的一点工作即可完成.
在一些情况下, 比如更新输入的文本, 这些文本已经被浏览器自己的编辑操作添加进 DOM 中(即浏览器已经修改了 DOM, Prosemirror 监听 DOM change 事件, 然后由此触发 transaction 将 DOM 的输入变化同步过来, 不需要再修改 DOM), 确保 Prosemirror 和 DOM 一致并不需要任何的 DOM 更新.(当这种同步 DOM 状态到 Prosemirror 的 transaction 被取消的时候, view 将会修改 undo DOM 去确保 DOM 和 state 保持同步)
相似地, DOM selection 只有在已经和 state 的 selection 过期的时候才会同步, 以避免破坏浏览器 selection 的各种隐藏的状态(比如在一个较短的行按向上或者向下箭头的时候的这个功能, 你的光标会跑到上一行或者下一行较长行的行尾)
Props
‘Props’ 是很有用的, 准确来说, 这个概念取自 React. Props 对 UI component 来说就像一个参数. 理想情况下, component 得到的 props 完全定义了它的行为.
1 | |
像上面这样, 当前的 state 是一个 prop. 控制 component 的代码(即给 component 传入 props 的代码——译者注)可以在不同时间 updates 其他的 props, 不过不包括 state, 因为 component 本身不会改变除了 state 的其他 props(因为这些应该让控制 component 的代码来更新——译者注). updateState 只是一个更新 state prop 的快捷方式.
Plugin 也可以 declare 一个 props, 不过不含 state 和 dispatchTransaction, 这俩只能直接在定义 view 的时候提供(Plugin 是允许定义 state 字段的, 表示 plugin 的状态, 这里说的 state 指的是 editor 的 state——译者注).
1 | |
当给的 prop 被(多个 Plugin 等)声明多次的时候, 这些 prop 如何被处理取决于它们自己. 总体来说, (editor view)直接提供的 props 优先, 之后按每个 plugin 声明的顺序处理. 对于一些 props 来说, 比如 domParser, 最先声明的值被使用, 之后声明的就被忽略了. 对于(props 的)处理函数来说, 返回一个 boolean 值表示它们是否处理该事件, 第一个返回 true 的处理该事件(然后其他同类型事件的处理函数被忽略——译者注). 最后, 对于另一些 props 来说, 比如 attributes(可以在 editable DOM 上设置 attributes), 和 decorations(下一节会讲到), 使用的是它们合并后的值.
Decorations
Decorations 给了你绘制你的 document view 方面的一些能力. 它们通过 decorations 属性的返回值被创建, 有三种类型:
- Node decorations 增加样式或者其他 DOM 属性到单个 node 的 DOM 上去.
- Widget decorations 在给定位置插入一个 DOM node, 其不是实际文档的一部分
- Inline decorations 在给定的 range 中的行内元素增加样式或者属性, 和 node decoration 类似, 不过只针对行内元素.
为了能够高效率的绘制和比较 decoration, 上述这些 decoration 需要以 decoration set (它是一个和真实文档结构类似的树状的数据结构)的形式来提供. 你可以通过静态方法 create 来新建, 提供给该函数当前文档和一个 decoration 数组的对象作为参数:
1 | |
当你有很多 decoration 的时候, 每次重绘的时候都在内存中创建一次 decoration set 代价会比较昂贵. 因此如果有这种情况出现的话, 推荐的方式是将你的 decoration 放到 plugin 的 state 中去维护, 然后在文档修改的时候去 map 它到新的文档状态, 然后只在你需要的时候更新它.
1 | |
示例中的插件初始化它的 state 为 decoration set, 该 decoration 每四个位置增加了一个黄色行内背景的 decoration. 这恐怕不是很有用, 但是类似这种的使用场景可以实现类似高亮搜索结果匹配或者增加评论区域等功能.
当一个 transaction 被应用到 state 的时候, 插件的 state 的 apply 方法 向前映射 decoration set, 使该 decoration set (生成的的元素)留在原地以"适应"新的文档结构. mapping 方法(常用来作用于本地改变)由于 decoration set 的树形结构而高效更新——只有被变化影响的节点才会被更新.
(在生产环境中的 plugin 的 apply 方法也会出现在当新的事件触发的 add 或者 remove decorations 的时候, 那个时候可以通过检查 transaction 携带的信息或者检查 plugin 上的 transaction 上附加的 meta 信息来检测)
最终, decorations 属性简单的返回 plugin 的 state, 这将使 decoration 显示在 view 中.
Node views
还有一种影响编辑器 view 如何绘制在你的 document 的方法. Node views 通过定义一系列小型且独立的 node 的 UI component 在 document 来实现. 它们(你定义的 node views 们)允许你定义如何渲染这些 DOM, 定义他们的更新方式, 并且写自定义的代码去响应事件.
1 | |
示例中 image 的 nodes view 对象为 image 创建了它自定义的 DOM 节点, 同时还添加了事件处理函数, 和一个 stopEvent 方法, 表示 Prosemirror 需要忽略来自该 DOM 节点的事件.
你会经常想要和 node 交互以影响 document 中的真实 node. 但是为了创建一个 transaction 去改变一个 node, 你首先需要知道这个 node 在哪儿. 为了让你能够做到这一点, node views 传递了一个 getter 函数 可以用来查询它们当前在 document 中的位置. 让我们修改下刚刚的示例, 使它能够在点击这个 node 的时候让你为这个 image 节点输入 alt 信息.
1 | |
setNodeMarkup 是一个可以被用来改变给定 position node 的类型或者属性的方法. 在上面的示例中, 我们使用 getPos 方法来查找 image 节点当前的 position, 然后给这个 node 一个新的属性和新的 alt 信息.
当一个 node 更新的时候, 默认行为是保留外层的 DOM 结构, 只把它的子元素和新的子元素集合进行比较, 然后按需更新或者替换它们. 一个 node view 可以覆盖这个默认的行为, 它允许我们基于 node 内容来做一些事情如更新段落的 css 类名等.
1 | |
Image 不会有内容, 因此在我们之前那个示例中, 我们不需要担心它的内容如何被渲染. 但是段落是有内容的. Node views 支持两种途径来操作它的内容: 你可以让 Prosemirror 来管理它, 或者你完全来手动管理它. 如果你提供了一个 contentDOM 属性, Prosemirror 将会把 node 的内容渲染到该属性节点里面, 然后处理 node 的内容更新. 如果你没有提供该属性, node 的内容对编辑器来说将变为一个黑盒, 你如何展示 node 的内容以及它如何与用户交互完全取决于你.
在这种情况下, 我们想要段落的内容的行为表现的像是一个正常的可编辑文本, 所以 contentDOM 的属性的定义和 dom 属性一样, 因为内容需要直接被渲染到外层容器中.
魔法发生在 update 方法 中. 需要首先说明的是, 这个方法完全决定 node view 如何被更新以展示变化后的 node. 被编辑器的更新算法绘制的新的 node 可能是任何东西, 因此你必须验证新绘制出来的节点能被当前 node view 处理.
示例中的 update 方法首先检查了新的 node 是否是一个段落, 如果不是的话直接中断. 然后根据新 node 的内容, 确认 empty 类名是否应该存在于节点上, 如果返回了 true 表示更新成功(此时 node 的内容将会被更新).
Commands
在 Prosemirror 的术语里, 一个 command 函数可以让用户通过按一些联合按键(如 cmd + a 全选——译者注)来执行操作或者菜单交互行为.
由于一些实际的原因, commands 略微有一些复杂. 一些简单的 commands 是一个函数, 其接受一个 eidtor state 和一个 dispatch (EditorView.dispatch 或者其他与 transactions 有关的的函数)作为参数, 然后返回一个 boolean 值. 下面是一个非常简单的示例:
1 | |
如果一个命令不可用, 它应该返回 false 然后什么也不做. 当它可用的时候, 它应该 dispatch 一个 transaction 然后返回 true. keymap 插件 使用该机制来阻止那些已经被其中一个 command 处理的按键被其他的 command 处理.
为了能够查询一个 command 是否能够被应用到给定的 state 而不真的执行该命令, 上述的 dispatch 参数是可选的, command 函数如果没有 dispatch 而其又可用的时候会仅仅返回 true 而不做其它的事情. 下面的示例展示这种情况:
1 | |
为了弄清当前的 selection 能否被删除, 你需要调用 deleteSelection(view.state, null), 而当你真的需要删除一个 selection 的时候, 调用变成了 deleteSelection(view.state, view.dispatch). 一个菜单栏可以使用此机制来决定菜单按钮是否应该置灰(表示不可用).
在上面说的菜单栏使用 commands 的时候, 它不会访问实际的 editor view——其实大多数情况下 command 都不需要访问, 它们甚至可以在没有 view 可用的时候通过设置进行菜单命令的应用和测试. 但是一些 commands 确实需要与 DOM 进行交互——它们可能需要 query 一个给定的 position 是否在一个 textblock 的末尾, 或者想要弹出一个相对于 view 定位的对话框. 因此, 大多数调用 commands 的 plugin 将会传递第三个参数, 即当前的 view.
1 | |
这个示例中(虽然很没用) 显示 commands 不需要 dispatch 一个 transaction——虽然它们通常被调用来应用它们所谓副作用, 即 dispatch 一个 transaction, 不过也可以被调用用来弹出一个对话框(而不 dispatch).
prosemirror-commands 模块提供了大量的编辑 commands, 从简单的 deleteSelection 的变体 command, 到更复杂的比如 joinBackward, 该命令实现了 block-joining 行为, 该行为发生在当你在 textblock 的行首按下退格键(backspace)的时候. 该模块还有一些 basic keymap (基本按键绑定), 绑定了大量的架构无关(即不区分 Win/Mac 或者不区分 Safari/Chrome 等)的 commands 到相应按键上.
在一些情况下, 不同的行为, 即使通常绑定到单个按键也会被放入不同的 commands 中(即一个按键可能在不同的情况由不同的 command 来处理——译者注). 工具函数函数 chainCommands 可用于组合多个命令——它们将一个接一个地尝试, 直到一个返回 true.
例如, 基本的按键映射绑定了退格键到 command chain deleteSelection (当 selection 非空的时候起作用), joinBackward (当光标在一个 textblock 开始地方的时候起作用), 然后是 selectNodeBackward (如果 schema 禁止正常的加入节点的操作的话选择在 selection 之前的节点). 当这些都没有被 apply 的时候, 浏览器则会执行其默认的行为, 这样处理对在一个 textblock 中按下退格键是比较合适的(这样原生的拼写检查和类似的一些东西才能正常工作)
commands 模块也导出了一些 command 构造函数, 比如 toggleMark, 它接受一个 mark 类型, 和一个可选的属性集合, 然后返回一个能够开关当前选区 mark 的 command 函数.
一些其他模块也会导出 command 函数, 比如 history 模块的 undo 和 redo 函数. 为了定制你自己的编辑器, 或者为了允许用户与自定义的 document node 交互, 你可能需要写你自己的 command 函数.
Collaborative editing
实时协同编辑允许多个用户同时编辑同一个 document. 用户对文档的修改立即作用于它们本地的 document, 然后把这些修改发送给其他人, 同时自动合并来自不同的人的不同变动(不需要手动解决冲突), 这种编辑体验可以不中断编辑, 而且文档最终总是保持一致.
这个指南描述了如何上手 Prosemirror 的协同编辑功能.
Algorithm
Prosemirror 的协同编辑系统使用了一个 central authority(中心鉴权)模式, 它决定各人的修改如何按顺序被应用在 document 上. 如果两个编辑器同时做出了修改, 这些修改都会交给这个 authority. authority 将会接受其中的一个修改, 然后对所有的编辑器广播这个改动. 其他的改动将不会被接受, 然后当编辑器从服务端接受了新的改动, 它需要 rebase 本地的改动到来自其他编辑器的最新改动版本, 然后试着再次提交它本地的改动(这里的 rebase 类似 git 的 rabase, 本地的修改保持不变(因为被服务器拒绝了), 然后将之前的编辑器文档更新到最新, 然后再次尝试提交自己的本地修改——再看服务器是否接受——译者注).
The Authority
central authority 的角色其实很简单, 它必须:
- 跟踪当前文档的版本
- 接受来自编辑器的变动, 当这些变动被应用的时候, 将这些变动放到它自己的改动列表中去
- 为编辑器提供一个途径, 让其能够接受一个给定的版本
让我们实现一个极简的 central authority, 它跟编辑器一样运行在 JavaScript 环境.
1 | |
当一个编辑器想要试着提交它们的改动到 authority 的时候, 它们会调用 authority 的 receiveSteps 方法. 传递它们最后收到的版本号, 和它们在这个版本上增加的新的改动, 以及它们的客户端 ID(该 ID 用来识别哪些改动来自它们自己).
当上面这步的提交被 authority 接受的时候, 客户端将会收到提醒因为 authority 通知它们有新的来自服务器的改动可用, 然后给它们各自的如何改动的步骤. 在真实的实现的 authority 中, 你也可以让 receiveSteps 返回一个状态, 然后立即确认它发送的改动步骤来作为优化手段(而不是傻等着服务端通知它如何改动——译者注). 但是上面这个机制(即等待服务器通知)是用来保证在不可靠网络的情况下有个兜底的解决方案, 因此你应该总是将等待接收来自服务器的改动这一行为作为兜底方案.
示例中的这个 authority 的实现会有一个无限增长的步骤数组, 它的长度表示当前的版本.
The collab Module
collab 模块导出了一个 collab 函数, 它返回一个插件用来追踪本地修改, 然后接受远程的改动, 同时还指示何时应该发送哪些改动到 authorty.
1 | |
collabEditor 函数新建了一个 editor view, 该 view 载入了 collab 插件. 每当 state 更新的时候, 它会检查是否有任何东西需要发送给 authority, 如果有的话, 就发送它.
它还注册了一个函数, 以在当新的修改步骤可用的时候会让 authority 调用之, 该函数函创建了一个 transaction 用来按照 authority 指示的步骤更新本地的编辑器.
当一个步骤集合被 authority 拒绝的时候, 它将会保持变动步骤的未确认状态直到——也许很快——我们从 authority 接受新的改动步骤的时候. 在这之后(即接受了新的改动之后), 因为 onNewSteps 回调调用了 dispatch, 因此将会触发我们的 dispatchTransaction 函数, 这使得它将会尝试再次提交它的改动.
这些就是全部了. 当然, 对于异步数据流(比如在 colab demo 中的长轮询或者 web sockets), 你会需要更复杂的通信和同步代码. 你可能会想要你的 authority 在一些时候丢掉一些步骤以减少内存消耗. 不过总体上来说这个小小的示例完整描述了 authority 应该有的实现.
博主说:
 我常常希望在面对人生中一些关键抉择的时候,有人可以告诉我最佳的做法,让我不至于白白浪费宝贵的时间。推己及人,我因此经常写博客,以期在浩渺无垠的互联网中的这个小小角落里记录下对于我来说只有一次的人生经历,希望能够帮到那些希望得到帮助的人。
我常常希望在面对人生中一些关键抉择的时候,有人可以告诉我最佳的做法,让我不至于白白浪费宝贵的时间。推己及人,我因此经常写博客,以期在浩渺无垠的互联网中的这个小小角落里记录下对于我来说只有一次的人生经历,希望能够帮到那些希望得到帮助的人。